쿠버네티스 워커노드 디스크 관리하기
최근 젠킨스 서버의 디스크 용량이 그동안 쌓인 도커 이미지 및 빌드 캐시 데이터들로 가득 차서 젠킨스에서 빌드가 제대로 되지 않는 문제를 겪었다.
해당 문제를 겪고 나서, 현재 사용 중인 텐센트 클라우드 TKE 클러스터의 워커 노드들의 디스크 용량도 확인해보았다.
현재 서비스에서는 2개의 워커노드를 사용하고 있는데 그 중 하나의 노드 디스크 용량이 80% 가량 차 있었다. 자세한 사용량을 파악하기 위해 해당 워커노드에 접속하여 df-h 명령어를 실행해보았다.
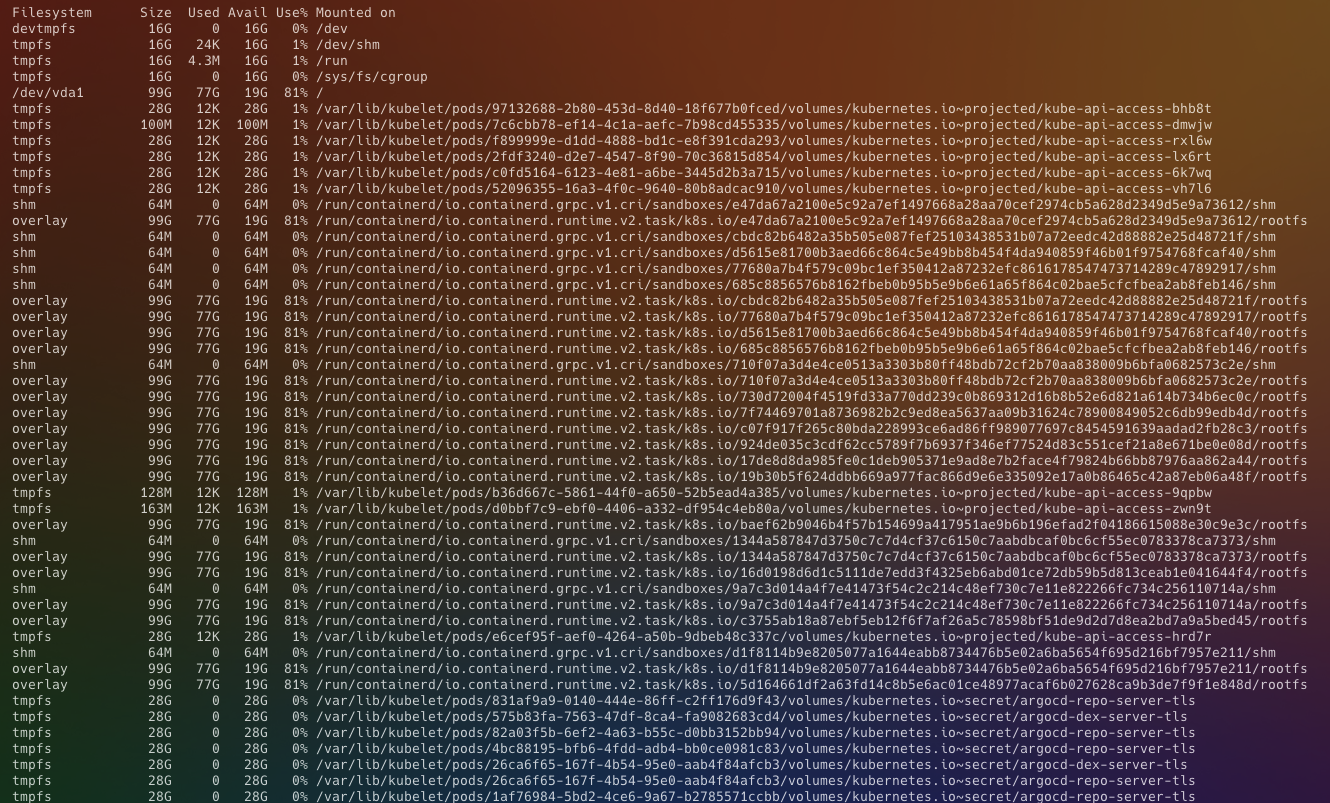
77GB를 사용하고 있는 경로가 /run/containerd/io.containerd.runtime.v2.task/k8s.io/ 인 것을 봤을 때, 젠킨스 서버와 마찬가지로 이미지 및 컨테이너 데이터가 많은 용량을 차지하고 있다는 것을 추측할 수 있었다.
여기서 많은 용량을 차지하고 있는 디렉토리의 경로가 /var/lib/docker/overlay2/ 가 아닌 /run/containerd/io.containerd.runtime.v2.task/k8s.io/ 인 이유는 쿠버네티스에서는 1.24 버전부터 컨테이너 런타임으로 Dockershim이 아닌 containerd를 사용하기 때문이다.
(쿠버네티스가 Docker 지원을 중단하고 containerd를 사용하게 된 이유와 맥락은 이 글에 잘 설명되어있다.)
워커노드에서는 containerd를 사용하고 있기 때문에, 만약 해당 VM에 접속해서 직접 커맨드를 실행하여 사용하지 않는 이미지 및 컨테이너 데이터를 제거하려면 docker cli가 아닌 ctr 혹은 nerdctl cli를 사용해야만 한다.
ctr cli를 통해 접속 중인 워커노드의 이미지를 조회하려면 k8s.io 네임스페이스의 이미지를 조회하여야 한다.
# ctr namespaces ls
NAME LABELS
k8s.io
# ctr -n k8s.io images ls 실행
쿠버네티스 가비지 콜렉션
물론 워커노드에 접속하여 직접 데이터를 정리할 수도 있겠지만, 그러면 디스크 용량이 찰 때마다 매번 수동으로 해당 작업을 진행 해야하기 때문에 자동화할 수 있는 방법에 대해 찾아보다가 쿠버네티스 공식 문서에서 garbage collection에 대한 내용을 발견하였다.
문서에 따르면, 가비지 콜렉션은 쿠버네티스가 클러스터 리소스를 정리하는 데 사용하는 다양한 메커니즘을 총칭한다. 가비지 콜렉션을 통해 정리할 수 있는 다양한 리소스 중에는 사용되지 않는 컨테이너 및 이미지도 포함되어있다.
사용되지 않는 이미지 가비지 콜렉션
kubelet은 사용되지 않는 이미지에 대해 5분 마다, 사용되지 않는 컨테이너에 대해 1분마다 가비지 콜렉션을 수행한다. 만약 외부의 가비지 콜렉션 도구를 사용하게 되면 kubelet의 동작이 중단되고 존재해야하는 컨테이너가 제거될 수 있으므로 권장되지 않는다.
이미지 가비지 콜렉션
쿠버네티스는 cadvisor의 도움을 받아 kubelet의 일부인 image manager를 통해 모든 이미지의 라이프 사이클을 관리한다. kubelet은 다음 2가지 디스크 사용량 제한을 고려하여 가비지 수집 결정을 내린다.
- HighThresholdPercent
- 디스크 사용량이 HighThresholdPercent 값을 초과하면 가비지 콜렉션이 트리거되어 마지막으로 사용된 시간을 기준으로 가장 오래된 순으로 이미지를 삭제한다.
- LowThresholdPercent
- 위에서 가비지 콜렉션이 트리거되면, 디스크 사용량이 LowThresholdPercent 값에 도달할 때까지 이미지를 삭제한다.
kubelet의 이미지 가비지 콜렉션 설정을 수정하기 위해서는 kubelet을 실행할 때 관련 옵션 플래그를 지정해야한다.
https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/ 문서를 참고하면 설정할 수 있는 옵션들을 찾을 수 있다.
--image-gc-high-threshold int32- 값(비율)은 [0, 100] 범위 내에 있어야 한다. 기본값 : 85
--image-gc-low-threshold int32- 값(비율)은 [0, 100] 범위 내에 있어야 한다. 기본값 : 80
image-gc-high-threshold 의 기본값은 85이기 때문에 디스크 사용량이 85%를 초과하면 가비지 콜렉션이 수행되겠지만 더 낮은 임계치를 적용하기 위해 현재 사용 중인 TKE 클러스터의 워커노드에 관련 설정을 적용해보았다.
kubelet의 systemd 유닛 파일인 /usr/lib/systemd/system/kubelet.service 을 확인해보았다.
[Unit]
Description=kubelet
[Service]
EnvironmentFile=-/etc/kubernetes/kubelet
ExecStart=/usr/bin/kubelet ${ANONYMOUS_AUTH} ${AUTHENTICATION_TOKEN_WEBHOOK} ${AUTHORIZATION_MODE} ${CLIENT_CA_FILE} ${CLOUD_CONFIG} ${CLOUD_PROVIDER} ${CLUSTER_DNS} ${CLUSTER_DOMAIN} ${CONTAINER_RUNTIME} ${CONTAINER_RUNTIME_ENDPOINT} ${EVICTION_HARD} ${FAIL_SWAP_ON} ${HOSTNAME_OVERRIDE} ${KUBE_RESERVED} ${KUBECONFIG} ${MAX_PODS} ${PROVIDER_ID} ${REGISTER_SCHEDULABLE} ${REGISTER_WITH_TAINTS} ${RUNTIME_REQUEST_TIMEOUT} ${SERIALIZE_IMAGE_PULLS} ${V}
ExecStartPost=-/bin/bash /etc/kubernetes/deny-tcp-port-10250.sh
Restart=always
RestartSec=10
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
내용을 살펴보면 kubelet의 실행 플래그들을 /etc/kubernetes/kubelet 에서 변수로 받아오는 것을 알 수 있다.
/etc/kubernetes/kubelet 에서 이미지 가비지 콜렉션 관련 플래그 변수들을 추가해주었다.
만약 디스크 용량이 70% 차면 60%가 될 때까지 사용되지 않는 이미지를 제거하도록 설정하였다.
IMAGE_GC_HIGH_THRESHOLD="--image-gc-high-threshold=70"
IMAGE_GC_LOW_THRESHOLD="--image-gc-low-threshold=60"
그리고 다시 /usr/lib/systemd/system/kubelet.service 에서 ExecStart에 추가한 변수를 사용하여 플래그를 지정해주었다.
ExecStart=/usr/bin/kubelet ${IMAGE_GC_HIGH_THRESHOLD} ${IMAGE_GC_LOW_THRESHOLD} ${ANONYMOUS_AUTH} ${AUTHENTICATION_TOKEN_WEBHOOK} ${AUTHORIZATION_MODE} ${CLIENT_CA_FILE} ${CLOUD_CONFIG} ${CLOUD_PROVIDER} ${CLUSTER_DNS} ${CLUSTER_DOMAIN} ${CONTAINER_RUNTIME} ${CONTAINER_RUNTIME_ENDPOINT} ${EVICTION_HARD} ${FAIL_SWAP_ON} ${HOSTNAME_OVERRIDE} ${KUBE_RESERVED} ${KUBECONFIG} ${MAX_PODS} ${PROVIDER_ID} ${REGISTER_SCHEDULABLE} ${REGISTER_WITH_TAINTS} ${RUNTIME_REQUEST_TIMEOUT} ${SERIALIZE_IMAGE_PULLS} ${V}
systemd 유닛 파일의 변경 사항을 적용하기 위해 systemctl daemon-reload 커맨드를 실행한 후에 systemctl restart kubelet 커맨드를 통해 kubelet을 재시작한다.
kubectl get node 명령어를 통해 kubelet을 재시작한 워커노드가 정상적으로 동작하고 있는지 확인한다.
이미지 가비지 콜렉션은 5분마다 수행되므로, 재시작 후 일정 시간이 지난 후에 가비지 콜렉션이 제대로 수행되는지 확인하기 위해 워커노드에서 df -h 로 디스크 상태를 확인해본다.
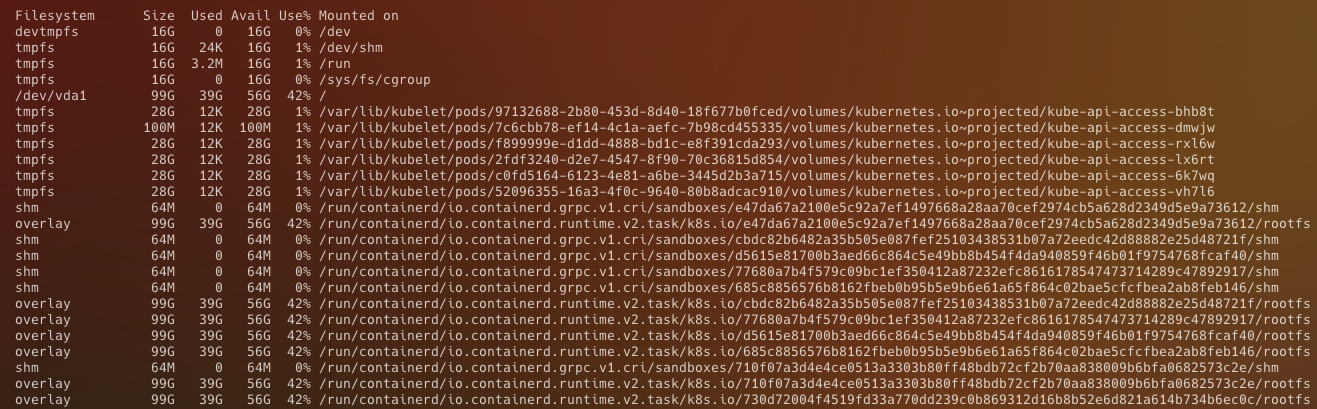
설정을 적용하기 전에 노드의 디스크 사용량은 80% 넘게 차 있었지만 현재는 디스크 사용량이 40% 정도로 줄고 /run/containerd/io.containerd.runtime.v2.task/k8s.io/ 의 용량이 대폭 줄어든 것을 확인할 수 있다.
좀 더 정확하게 가비지 콜렉션이 수행 됐는지 확인하기 위해 journalctl -u kubelet -n 100 커맨드를 통해 kubelet의 최신 로그 100개를 조회해보자.
I1018 17:16:49.127741 2313004 image_gc_manager.go:312] "Disk usage on image filesystem is over the high threshold, trying to free bytes down to the low threshold" usage=82 highThre>
I1018 17:16:49.130385 2313004 image_gc_manager.go:389] "Removing image to free bytes" imageID="sha256:047cf9fbdf261c42fec5d0db43e161b15ce7456f4cea37fdad98d8fae840079f" size=1042721>
I1018 17:16:49.159122 2313004 image_gc_manager.go:389] "Removing image to free bytes" imageID="sha256:22f6921b0b710e16b011ca3bfb00b45037729cf7d0892ccb419586aa7e313c22" size=23963887
I1018 17:16:49.182128 2313004 image_gc_manager.go:389] "Removing image to free bytes" imageID="sha256:09b1f1bf150850e55c1ba343af8fcd7d229006fe1b421b047b0d31f9db82a06e" size=1001151>
I1018 17:16:49.236277 2313004 image_gc_manager.go:389] "Removing image to free bytes" imageID="sha256:e1317ccb493705380ee4deeac10682e09a8fd9c107ed0430bd4adcb0a01c9445" size=1052505>
로그의 내용을 보면 image_gc_manager에 의해 디스크 사용량(82%)이 high threshold를 초과하여 low threshold까지 용량을 확보한다는 메시지와 실제 삭제된 이미지 로그들을 확인할 수 있다.