네트워크 계층
데이터 링크 계층의 한계
물리 계층과 데이터 링크 계층만으로는 다른 네트워크까지의 도달 경로를 파악하기 어렵다.
패킷이 이동할 최적의 경로를 결정하는 것을 라우팅이라고 한다. 물리 계층과 데이터 링크 계층의 장비로는 라우팅을 수행할 수 없지만, 네트워크 계층의 장비로는 가능하다.
MAC 주소만으로는 모든 네트워크에 속한 호스트의 위치를 특정하기 어렵다.
택배의 수신인 역할을 하는 정보가 MAC 주소라면, 수신지 역할을 하는 정보는 네트워크 계층의 IP 주소이다. MAC 주소는 일반적으로 NIC마다 할당되는 고정된 주소이지만, IP 주소는 호스트에 직접 할당이 가능하다. DHCP 프로토콜을 통해 자동으로 할당받거나 사용자가 직접 할당할 수 있고, 한 호스트가 복수의 IP 주소를 가질 수도 있다.
IP (Internet Protocol)
기능
IP의 기능은 다양하지만 대표적인 기능으로는 IP 주소 지정과 IP 단편화가 있다.
IP 주소 지정
IP 주소를 바탕으로 송수신 대상을 지정하는 것을 의미한다.
IP 단편화
전송하고자 하는 패킷의 크기가 MTU라는 최대 전송 단위보다 클 경우, 이를 MTU 크기 이하의 복수의 패킷으로 나누는 것을 의미한다. MTU(Maximum Transmission Unit)란 네트워크에서 한 번에 전송 가능한 IP 패킷(IP 패킷 헤더 포함)의 최대 크기로 일반적으로 1500 바이트이다. MTU 크기 이하로 나누어진 패킷은 수신지에 도착하면 다시 재조합된다.
IP 단편화를 피하는 방법
데이터가 여러 패킷으로 쪼개지면 자연스레 전송해야할 패킷의 헤더들도 많아지고, 이는 불필요한 트래픽 증가와 대역폭 낭비로 이어질 수 있다. 또 쪼개진 IP 패킷들을 하나로 합치는 과정에서 발생하는 부하도 성능 저하를 야기할 수 있다. 때문에 IP 단편화는 되도록 하지 않는 것이 좋다.
IP 단편화를 피하려면 IP 단편화 없이 주고 받을 수 있는 최대 크기만큼만 전송해야 한다. 이 크기를 경로 MTU(Path MTU)라고 한다. 경로 MTU를 구하고 해당 크기만큼만 송수신하여 IP 단편화를 회피하는 기술을 경로 MTU 발견(Path MTU Discovery)라고 한다. 오늘날 네트워크에서는 대부분 이를 지원하고, 처리 가능한 최대 MTU 크기도 대부분 균일하기 때문에 IP 단편화는 자주 수행되지 않는다.
IPv4
IPv4 주소는 4바이트(32비트)로 표현되고, 0-255 범위의 네 개의 10진수로 표기되는 주소이다. 각 10진수는 .으로 구분되며, 점으로 구분된 8비트를 옥텟(octet)이라고 한다.
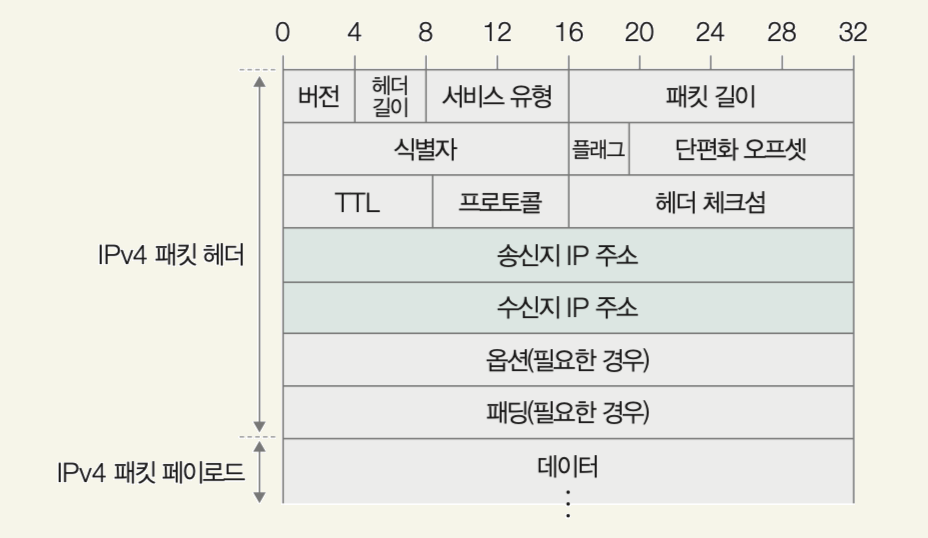
IPv4 헤더
식별자
단편화된 패킷들의 재조합을 위해 패킷에 할당된 번호
플래그
총 3비트로 구성된 IP 헤더의 필드이다. 첫 번째 비트는 항상 0으로 예약된 비트로, 사용되지 않는다. 두 번째 비트는 DF(Don't Fragment) 비트로, 1이면 단편화 금지를 의미하며 세 번째 비트는 MF(More Fragment) 비트로, 1이면 쪼개진 패킷이 더 있다는 것을 의미한다.
단편화 오프셋
패킷이 단편화되기 전 패킷의 초기 데이터에서 몇 번째로 떨어진 패킷인지를 나타내는 필드로, 패킷을 순서대로 재조합하기 위해 사용된다.
TTL (Time To Live)
패킷의 수명을 의미하는 필드로, 패킷이 한 홉을 거칠 때마다 TTL이 1씩 감소하다가 0이 되면 해당 패킷은 폐기된다. 홉(hop)은 패킷이 호스트 또는 라우터에 한 번 전달되는 것을 말한다. 무의미한 패킷이 네트워크상에 지속적으로 남아있는 것을 방지하기 위한 필드이다.
프로토콜
상위 계층의 프로토콜이 무엇인지를 나타내는 필드이다. 예를 들어 전송 계층의 대표적인 프로토콜인 TCP는 6번, UDP는 17번이다.
IPv6
IPv4의 주소 고갈 문제를 해결하기 위해 개발된 IP 프로토콜로 IPv6 주소는 16바이트(128비트)로 표현되고, 콜론(:)으로 구분된 8개 그룹의 16진수로 표현된다.
IPv6 헤더
다음 헤더 (next header)
상위 계층의 프로토콜을 가리키거나 확장 헤더를 가리킨다. IPv6는 추가적인 헤더 정보가 필요한 경우에 기본 헤더와 더불어 확장 헤더라는 추가 헤더를 가질 수 있다. IPv6는 IPv4와 달리 기본 헤더에 단편화 관련 필드가 없고, 단편화 확장 헤더를 통해 단편화가 이루어진다.
홉 제한 (hop limit)
IPv4 패킷의 TTL 필드와 유사하게 패킷의 수명을 나타내는 필드이다.
ARP (Address Resolution Protocol)
ARP는 IP 주소를 MAC 주소에 대응하는 프로토콜로 네트워크 내에 있는 송수신 대상의 IP 주소를 통해 MAC 주소를 알아낼 수 있다.
호스트 A와 B가 동일한 네트워크에 속한 상태에서 A가 B에게 패킷을 보내고 싶은 상황에서 ARP의 동작 과정은 다음과 같다.
ARP 요청
A는 네트워크 내의 모든 호스트에게 브로드캐스트 메시지를 보낸다. 이 메시지는 ARP 요청이라는 ARP 패킷이다.
ARP 응답
네트워크 내의 모든 호스트가 ARP 요청 메시지를 수신하지만, B를 제외한 나머지 호스트는 자신의 IP 주소가 아니므로 이를 무시한다. B는 자신의 MAC 주소를 담은 메시지를 A에게 전송한다. 이 유니캐스트 메시지는 ARP 응답이라는 ARP 패킷이다.
ARP 테이블 갱신
ARP를 활용할 수 있는 모든 호스트는 ARP 테이블 정보를 유지한다. ARP 테이블은 IP 주소와 그에 맞는 MAC 주소 테이블을 대응하는 표이다. A는 B의 MAC 주소를 알게 되면 호스트 B의 IP 주소와 MAC 주소의 연관 관계를 ARP 테이블에 추가한다. 앞으로 A는 B와 통신할 때 굳이 브로드캐스트로 ARP 요청을 보낼 필요가 없어진다.
다른 네트워크에 속한 호스트에게 패킷을 보내야할 경우 네트워크 외부로 나가기 위한 장비(라우터)의 MAC 주소를 알아내어 패킷을 전송한다.
IP 주소
하나의 IP 주소는 크게 네트워크 주소와 호스트 주소로 이루어진다.
- 네트워크 주소 : 호스트가 속한 특정 네트워크를 식별하는 역할을 수행한다.
- 호스트 주소 : 네트워크 내에서 특정 호스트를 식별하는 역할 수행핸다.
호스트 주소가 전부 0인 IP 주소와 호스트 주소가 전부 1인 IP 주소는 특정 호스트를 지칭하는 IP주소로 활용할 수 없다. 전자는 해당 네트워크 자체를 의미하는 네트워크 주소로 사용되고, 후자는 브로드캐스트를 위한 주소로 사용된다.
클래스풀 주소 체계 (Classful addressing)
클래스는 네트워크 크기에 따라 IP 주소를 분류하는 기준이다. 클래스를 기반으로 IP 주소를 관리하는 주소 체계를 클래스풀 주소 체계라고 한다.
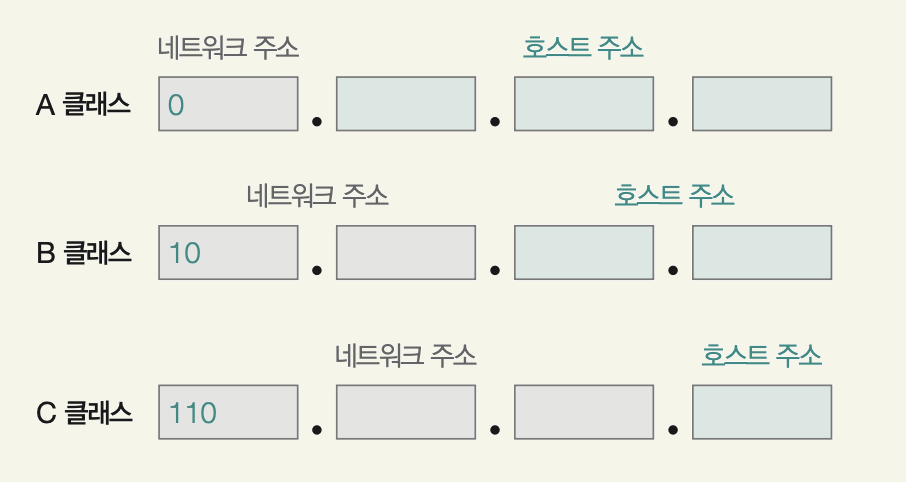
A 클래스
네트워크 주소는 비트 '0'으로 시작하고 1옥텟으로 구성되며, 호스트 주소는 3옥텟으로 구성된다. 2^7(128)개의 A 클래스 네트워크가 존재할 수 있고, 각 네트워크는 2^24 - 2(16,777,214)개의 호스트를 할당할 수 있다. 0.0.0.0 ~ 127.255.255.255
B 클래스
네트워크 주소는 비트 '10'으로 시작하고 2옥텟으로 구성되며, 호스트 주소도 2옥텟으로 구성된다. 2^14(16,384)개의 B 클래스 네트워크가 존재할 수 있고, 각 네트워크는 2^16 - 2(65,534)개의 호스트를 할당할 수 있다. 128.0.0.0 ~ 191.255.255.255
C 클래스
네트워크 주소는 비트 '110'으로 시작하고 3옥텟으로 구성되며, 호스트 주소는 1옥텟으로 구성된다. 2^21(2,097,152)개의 C 클래스 네트워크가 존재할 수 있고, 각 네트워크는 2^8 - 2(254)개의 호스트를 할당할 수 있다. 192.0.0.0 ~ 223.255.255.255
클래스리스 주소 체계 (Classless Addressing)
클래스 개념 없이 클래스에 구애받지 않고 네트워크의 영역을 나누어서 호스트에게 IP 주소 공간을 할당하는 방식이다. 클래스풀 주소 체계보다 더 유동적이고 정교하게 네트워크를 구획할 수 있다.
서브넷 마스크 (Subnet Mask)
클래스리스 주소 체계에서는 네트워크와 호스트를 구분 짓는 수단으로 서브넷 마스크를 이용한다. 서브넷 마스크는 IP 주소상에서 네트워크 주소는 1, 호스트 주소는 0으로 표기한 비트열을 의미한다. 네트워크 내의 부분적인 네트워크(서브네트워크)를 구분 짓는(마스크) 비트열인 셈이다. 서브넷 마스크를 이용해 클래스를 원하는 크기로 더 잘게 쪼개어 사용하는 것을 서브네팅(subnetting)이라고 한다. 예를 들어, 255.255.255.0이라는 서브넷 마스크는 앞의 세 옥텟(24비트)이 네트워크 주소임을 의미한다.
CIDR (Classless Inter-Domain Routing notation) 표기법
'IP 주소/서브넷 마스크상의 1의 개수'로 서브넷 마스크를 표기하는 방식이다. 예를 들어, 서브넷 마스크 255.255.255.0를 2진수로 표기하면 11111111.11111111.11111111.00000000이다. 1이 총 24개이므로 CIDR 표기법을 따르면 /24로 표기할 수 있다.
공인 IP 주소와 사설 IP 주소
공인 IP 주소
전 세계에서 고유한 IP 주소로, 네트워크 간의 통신(인터넷)에서 사용되는 IP 주소이다. ISP나 공인 IP 주소 할당 기관을 통해 할당받을 수 있다.
사설 IP 주소
사설 네트워크에서 사용하기 위한 IP 주소이다. 사설 네트워크란 인터넷, 외부 네트워크에 공개되지 않은 네트워크를 의미한다. 사설 IP 주소의 할당 주체는 일반적으로 라우터이다. 할당받은 사설 IP 주소는 해당 호스트가 속한 사설 네트워크상에서만 유효한 주소이므로, 다른 네트워크상의 사설 IP 주소와 중복될 수 있다. IP 주소 공간 중에서 사설 IP 주소로 사용하도록 예약된 IP 주소 공간이 있다.
- 10.0.0.0 ~ 10.255.255.255
- 172.16.0.0 ~ 172.31.255.255
- 192.168.0.0 ~ 192.168.255.255
NAT (Network Address Translation)
IP 주소를 변환하는 기술로, 주로 네트워크 내부에서 사용되는 사설 IP 주소와 네트워크 외부에서 사용되는 공인 IP 주소를 변환하는 데 사용된다. NAT을 통해 사설 IP 주소를 사용하는 여러 호스트는 적은 수의 공인 IP 주소를 공유할 수 있다. 대부분의 라우터와 가정용 공유기는 NAT 기능을 내장하고 있다.
정적 IP 주소와 동적 IP 주소
호스트에 IP 주소를 할당하는 방법에는 정적 할당과 동적 할당이 있다. 전자는 수작업을 통해 이루어지고, 후자는 DHCP라는 프로토콜을 통해 이루어진다.
정적 할당
호스트에 직접 수작업으로 IP 주소를 부여하는 방식이다. 이렇게 할당된 IP 주소를 정적 IP 주소라고 부른다.
동적 할당
정적 할당과는 달리 호스트에 IP 주소가 동적으로 할당되는 방식이다. 이렇게 할당된 IP 주소를 동적 IP 주소라고 부른다.
DHCP (Dynamic Host Configuration Protocol)
IP 동적 할당에 사용되는 대표적인 프로토콜이다. DHCP를 통한 IP 주소 할당은 IP 주소를 할당받고자 하는 호스트와 해당 호스트에게 IP 주소를 제공하는 DHCP 서버 간에 메시지를 주고받음으로써 이루어진다. 여기서 DHCP 서버의 역할은 일반적으로 라우터(공유기)가 수행하지만, 특정 호스트에 DHCP 서버 기능을 추가할 수도 있다.
예약 주소
127.0.0.0/8은 루프백 주소로 자기 자신을 가리키는 특별한 주소이다. 주로 127.0.0.1 주소가 사용된다. 루프백 주소로 전송된 패킷은 자기 자신에게 되돌아오므로 자기 자신을 마치 다른 호스트인 양 간주하여 패킷을 전송할 수 있다.
0.0.0.0/8은 호스트가 IP 주소를 할당받기 전에 임시로 사용 가능한 예약 IP 주소이다.
라우터 (Router)
라우터의 핵심 기능은 패킷이 이동할 최적의 경로를 설정한 뒤 해당 경로로 패킷을 이동시키는 것이다. 이를 라우팅이라고 한다. 멀리 떨어져 있는 호스트 간의 통신 과정에서 패킷은 서로에게 도달하기까지 여러 라우터를 거쳐서 다양한 경로로 이동할 수 있다. 라우팅 도중 패킷이 호스트와 라우터 간에, 혹은 라우터와 라우터 간에 이동하는 하나의 과정을 홉(hop)이라고 부른다. 즉, 패킷은 여러 홉을 거쳐 라우팅될 수 있다.
라우팅 테이블 (Routing Table)
라우팅 테이블은 특정 수신지까지 도달하기 위한 정보를 명시한 표와 같은 정보로, 라우터는 라우팅 테이블을 참고하여 수신지까지의 도달 경로를 판단한다.
- 수신지 IP 주소와 서브넷 마스크 : 최종적으로 패킷을 전달할 대상을 의미한다.
- 다음 홉 (next hop) : 최종 수신지까지 가기 위해 다음으로 거쳐야 할 호스트의 IP 주소나 인터페이스를 의미한다. 게이트웨이라고 명시되기도 한다.
- 네트워크 인터페이스 : 패킷을 내보낼 통로이다. 인터페이스(NIC) 이름이 직접적으로 명시되거나 인터페이스에 대응하는 IP 주소가 명시되기도 한다.
- 메트릭 (metric) : 특정 경로로 패킷을 이동시키기 위해 드는 비용이다. 메트릭이 낮은 경로가 선호된다.
라우팅 테이블에 없는 경로로 패킷을 전송해야할 때, 기본적으로 패킷을 내보낼 경로를 설정하여 해당 경로로 패킷을 내보낼 수 있다. 이 기본 경로를 디폴트 라우트라고 한다.
정적 라우팅과 동적 라우팅
라우팅 테이블이 만들어지는 방법에는 정적 라우팅과 동적 라우팅이 있다.
- 정적 라우팅 : 사용자가 수동으로 직접 채워 넣은 라우팅 테이블의 항목을 토대로 라우팅 되는 방식이다.
- 동적 라우팅 : 자동으로 라우팅 테이블 항목을 만들고, 이를 이용하여 라우팅하는 방식이다.
동적 라우팅 프로토콜
동적 라우팅에서 라우터는 특정 수신지까지 도달하기 위한 최적의 경로를 찾아 라우팅 테이블에 추가하기 위해 라우터끼리 서로 자신의 정보를 교환하게 되는데, 이 과정에서 사용되는 프로토콜이 동적 라우팅 프로토콜이다.
AS 내의 라우팅이 가능한 프로토콜(RIP, OSPF)과 AS 간의 라우팅이 가능한 프로토콜(BGP) 존재한다. AS(Autonomous System)은 동일한 라우팅 정책으로 운용되는 라우터들의 집단 네트워크이다.
IGP (Interior Gateway Protocol) : AS 내부에서 수행되는 라우팅 프로토콜이다.
RIP (Routing Information Protocol) : 거리 벡터를 사용하는 라우팅 프로토콜이다. 거리 벡터(distance vector) 라우팅 프로토콜이란 거리를 기반으로 최적의 경로를 찾는 라우팅 프로토콜로, 여기서 거리는 패킷이 경유한 라우터의 수, 즉 홉의 수를 의미한다. RIP는 인접한 라우터끼리 경로 정보를 주기적으로 교환하며 라우팅 테이블을 갱신한다. 홉 수가 적을수록 라우팅 테이블상의 메트릭 값도 작아진다.
OSPF (Open Shortest Path First) : 링크 상태 라우팅 프로토콜이다. 링크 정보를 비롯한 현재 네트워크 상태를 그래프의 형태로 링크 상태 데이터베이스에 저장하여 이를 기반으로 최적의 경로를 선택한다. OSPF에서는 최적의 경로를 결정하기 위해 대역폭을 기반으로 메트릭을 계산한다. 대역폭이 높은 링크일수록 메트릭이 낮은 경로로 인식한다. 또한 라우터 간에 경로 정보를 주기적으로 교환하여 라우팅 테이블을 갱신하는 RIP와 달리, OSPF는 네트워크의 구성이 변경되었을 때 라우팅 테이블이 갱신된다. 네트워크의 규모가 커졌을 때를 대비해서 AS를 에어리어(area)라는 단위로 나누고 구분된 에어리어 내에서만 링크 상태를 공유한다.
EGP (Exterior Gateway Protocol) : AS 외부에서 수행되는 라우팅 프로토콜이다.
BGP (Border Gateway Protocol) : AS 간의 통신에서 사용되는 대표적인 프로토콜로, 엄밀하게는 AS 간의 통신도 가능한 프로토콜이다. 따라서 BFP로 AS 내 라우터 간 통신도 가능하다. BGP는 RIP와 OSPF에 비해 최적의 경로를 결정하는 과정이 복잡하고, 일정하지 않은 경우가 많다. 경로 결정 과정에서 수신지 주소와 더불어 다양한 속성과 정책이 고려되기 때문이다. BGP의 속성이란 경로에 대한 일종의 부가 정보이다.
- AS-PATH 속성 : 메시지가 수신지에 이르는 과정에서 통과하는 AS들의 목록이다.
- NEXT-HOP 속성 : 다음으로 거칠 라우터의 IP 주소
- LOCAL-PREF 속성 : AS 외부 경로에 있어서 AS 내부에서(local) 어떤 경로를 선호할지(preference)에 대한 척도를 나타내는 속성
BGP는 AS 간 라우팅을 할 때 거치게 될 라우터의 수가 아닌 AS의 수를 고려한다. 따라서 AS-PATH 길이가 더 짧은 경로라 할지라도 거치게 될 라우터의 홉 수가 더 많을 수 있다. 또 BGP는 RIP처럼 단순히 수신지에 이르는 거리가 아닌, 메시지가 어디를 거쳐 어디로 이동하는지를 나타내는 경로를 고려한다. 거리가 아닌 경로를 고려하는 이유는 메시지가 같은 경로를 무한히 반복하며 이동하는 순환을 방지하기 위함이다.
참조
https://www.hanbit.co.kr/store/books/look.php?p_code=B3633191758